Revolutionizing Speaker Diarization: The World's First Multimodal AI by Memories.ai
The world's first multimodal speaker diarization technology is here.
AI That Truly Understands Who Is Speaking
Imagine a world where AI truly understands who is speaking — not just what is being said. A world where machines identify individuals with the same intuitive grasp as humans.
At Memories.ai, we're thrilled to announce a monumental leap forward in artificial intelligence: the world's first multimodal speaker diarization technology.
This isn't just an upgrade. It's a complete reinvention of how AI processes human interaction — setting a new standard for AI video transcription, speaker recognition, and embodied AI applications globally.
The Limitations of Traditional Speaker Diarization
For years, speaker diarization — the process of identifying who spoke when in an audio recording — relied solely on sound. While impressive for its time, this audio-only approach faced significant hurdles:
- Voice variability — A single person's voice can change dramatically due to emotions, different microphones, or varying acoustic environments.
- Session inconsistency — Tracking a speaker reliably across multiple sessions or different recording conditions became unreliable.
- The human-intuition gap — Unlike humans, who use both sight and sound to identify speakers, AI was missing a crucial piece of the puzzle.
These challenges meant that achieving truly accurate and stable speaker identification, especially in complex scenarios, remained elusive.
Introducing Multimodal Speaker Diarization: The Human-Like Approach
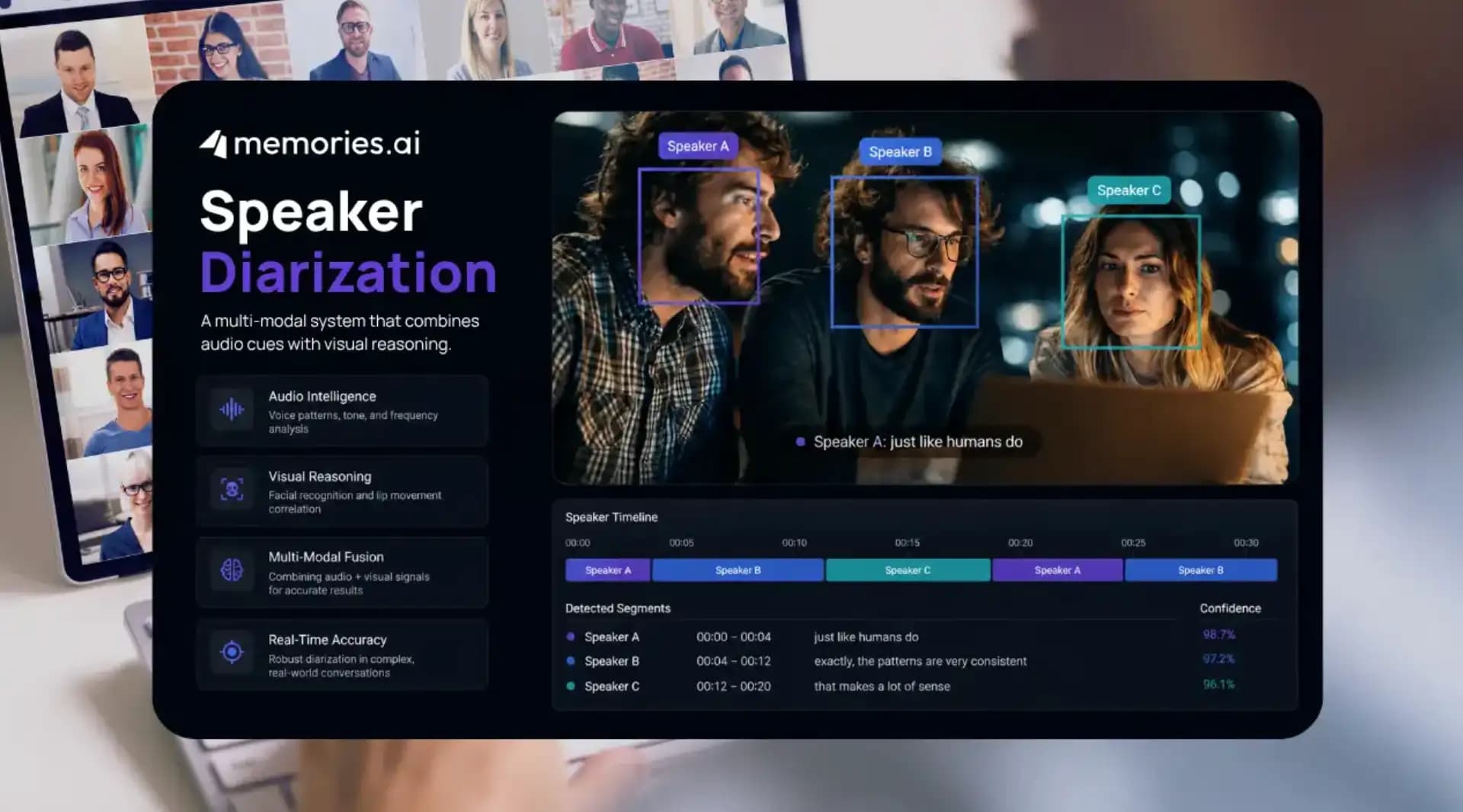
Memories.ai has reimagined diarization by integrating visual intelligence. Our groundbreaking multimodal system combines sophisticated audio cues with advanced visual reasoning and persistent human-identity memory.
Here's how it works — just like humans do:
- Audio analysis. Our system meticulously processes vocal patterns, pitch, and timbre from the audio track.
- Visual recognition. Simultaneously, it analyzes video feeds, identifying faces, tracking head movements, and correlating visual presence with speech.
- Persistent identity. By building a consistent visual memory of each individual, the system maintains accurate speaker identification even when voices change or environments shift.
This powerful combination allows our AI to deliver accurate and stable diarization across sessions, days, and diverse environments — even amidst noise and chaos.
Unmatched Benefits for a Connected World
Our multimodal AI speaker diarization offers unparalleled advantages across a wide range of applications:
- Superior accuracy — Dramatically reduces errors in speaker attribution, even in challenging conditions.
- Enhanced reliability — Provides stable speaker tracking over long periods and multiple interactions.
- Robustness in noise — Performs exceptionally well in noisy environments where traditional methods struggle.
- Global applicability — Designed to understand and differentiate speakers across various accents and demographics, making it a truly global solution for AI speech recognition.
Paving the Way for the Next Generation of AI
The implications of this technology extend far beyond improved transcription. As AI smart glasses, wearables, robots, and humanoids become more common, the need for machines to reliably understand who is speaking becomes paramount.
Our multimodal processing is a perfect fit for the next generation of embodied AI, enabling:
- Intuitive human–robot interaction. Robots can identify and address individuals directly, personalizing every interaction.
- Advanced smart devices. Wearables and smart glasses can understand group conversations and attribute speech correctly.
- Intelligent meeting summaries. Accurate speaker identification in video conferences and in-person meetings leads to more valuable, actionable transcripts.
Experience the Future of Video Transcription
Our multimodal system is at the heart of our Video Transcription service. Convert video and audio into text with not just speech recognition, but also visual description and summarization — all while accurately identifying each speaker.
This innovative technology makes it easier than ever to analyze, search, and understand your video content — whether for business intelligence, educational purposes, or personal archives.
Ready to experience the future of speaker diarization and video transcription?
Visit memories.ai/transcription today to learn more about our multimodal processing and explore how it can transform your workflow and unlock new possibilities for AI.
Read more

Memories.ai Research Fellowship Summer 2026
Applications open for the Memories.ai Research Fellowship — a 12-week intensive program for researchers building the future of visual AI. Remote-friendly. June 1 – August 30, 2026.
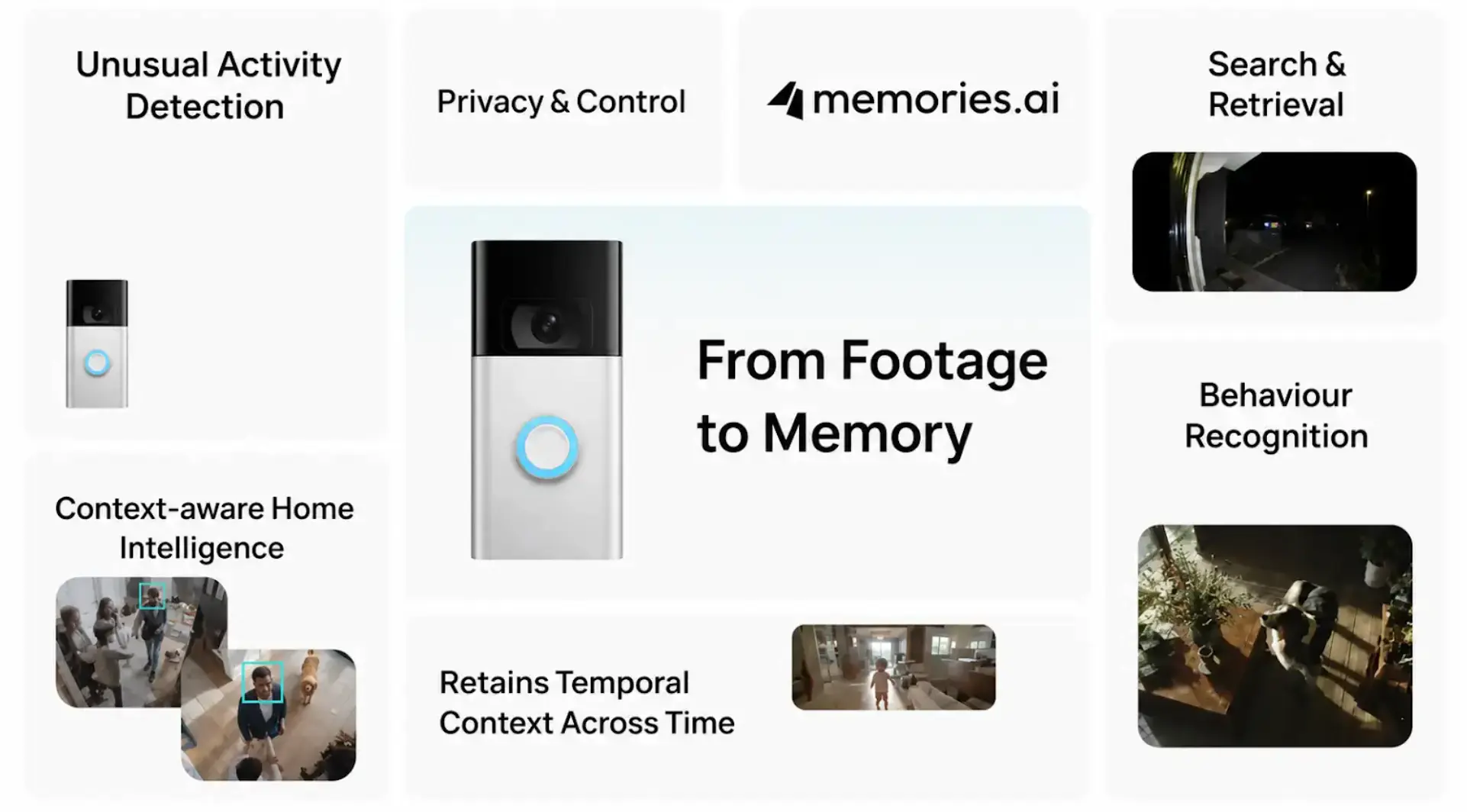
Beyond Basic Descriptions: Why Memories.ai Outsmarts General AI for Your Ring Doorbell Security
How Memories.ai's specialized visual memory AI offers superior security camera intelligence compared to general models like Gemini 3.0 Pro — proactive alerts, persistent person tracking, and evolving memory for your Ring doorbell.

Unlock Smarter Home Security: Memories.ai Brings AI Intelligence & Visual Memory to Your Ring Camera
Discover how Memories.ai transforms your Ring camera into an intelligent guardian with visual memory — smart pet monitoring, proactive security alerts, and affordable AI-powered video analytics.