Introducing the World's First Large Visual Memory Model
See BlogIntroducing the World's First Large Visual Memory Model
See BlogIntroducing the World’s First Large Visual Memory Model
Today, we are thrilled to introduce the world’s first Large Visual Memory Model. It is designed to equip all multi-modal large language models (LLMs) with the capability for virtually limitless visual memory recall. As the pioneering Large Visual Memory Model, we are moving beyond time-constrained memory limitations, truly ushering in an era where AI begins to possess unlimited visual memory.
For the first time, our model can retrieve visual memories. This includes dissecting user intent, precisely retrieving relevant visual memory segments, integrating all associated visual memory information, and performing in-depth reasoning based on these memories and the user's query.
Our model intelligently determines when, how, and which visual memories to retrieve. Following the integration of memory information, it generates detailed and thoughtful memory references in an efficient manner and the correct output format, thereby supporting the answering of any user question. This empowers multi-modal large models with infinitely long visual memory contexts, representing a significant stride towards Artificial General Intelligence (AGI).
What’s Changed
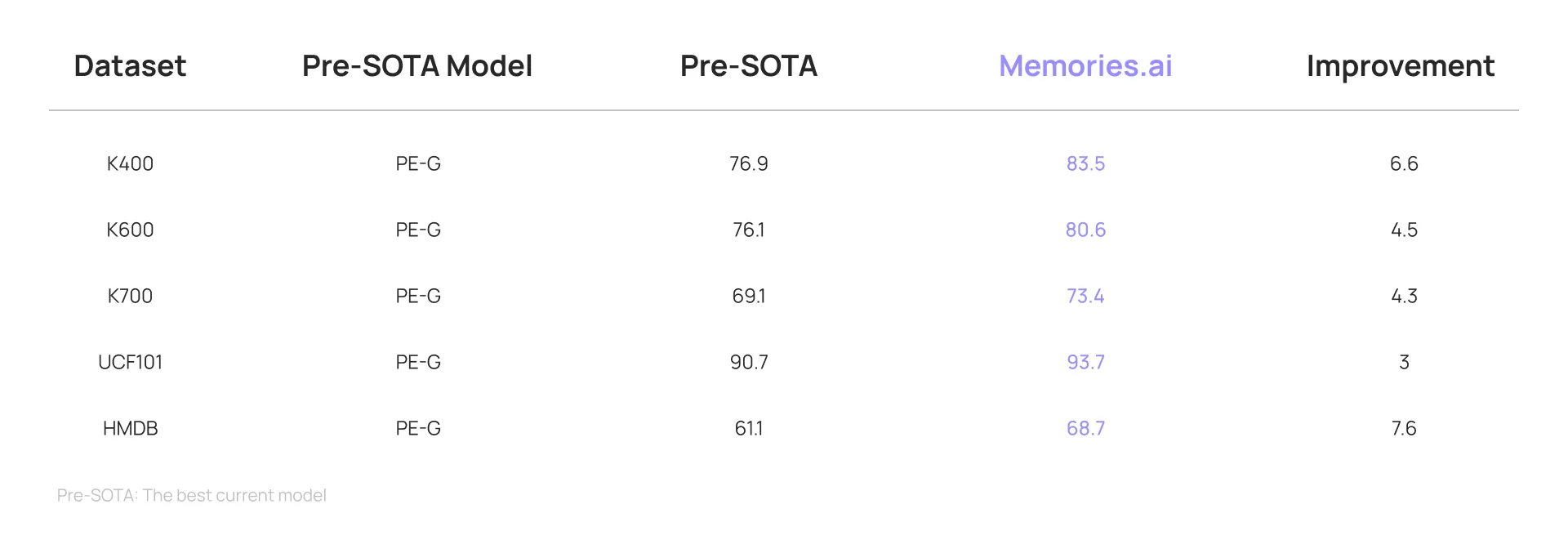
Our Large Visual Memory Model has achieved groundbreaking advancements in video classification, video retrieval, and video question answering. It has set new State-of-the-Art (SOTA) benchmarks across various evaluations, including:
The exceptional performance of our Large Visual Memory Model in visual memory retrieval makes it particularly well-suited for complex queries that necessitate extensive content retrieval as supplementary reference.
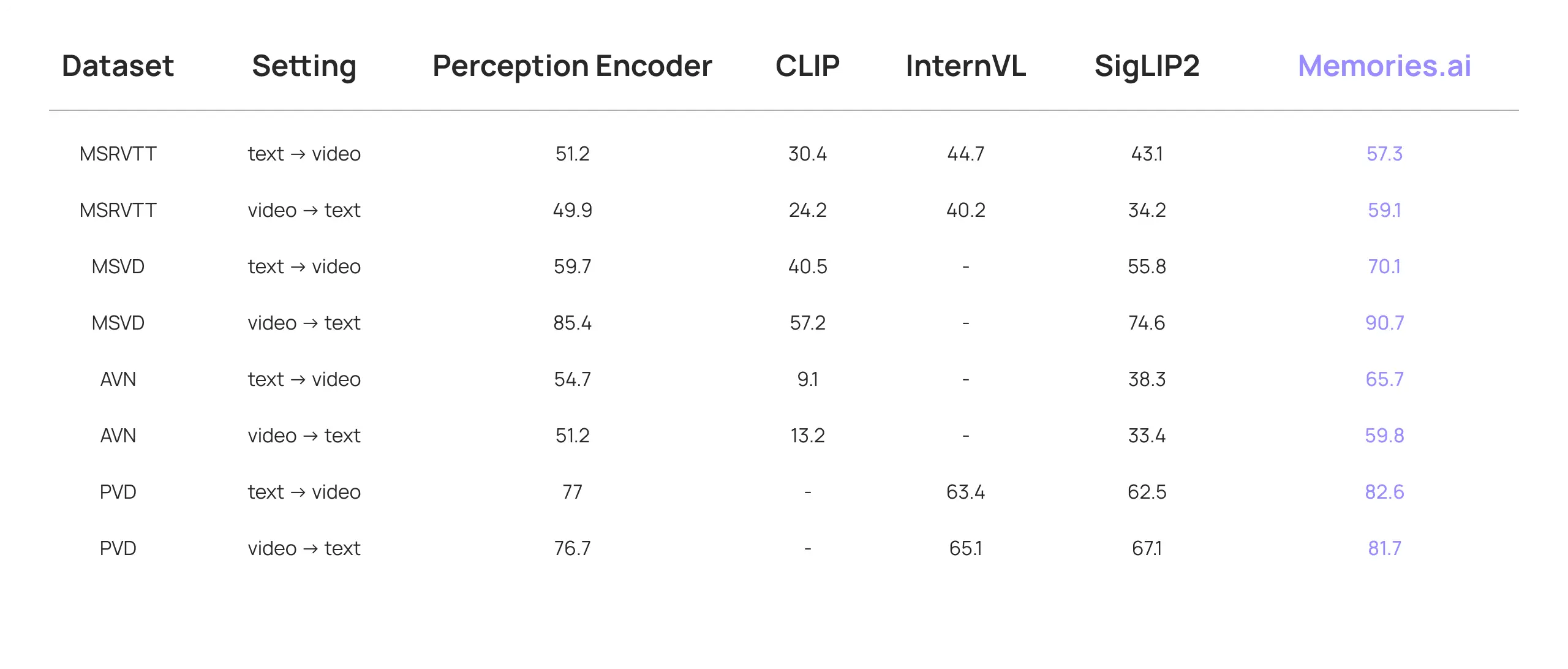
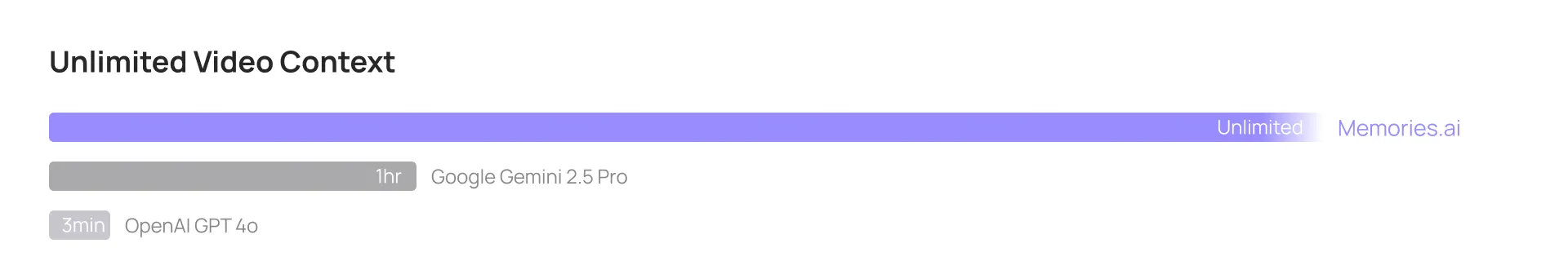
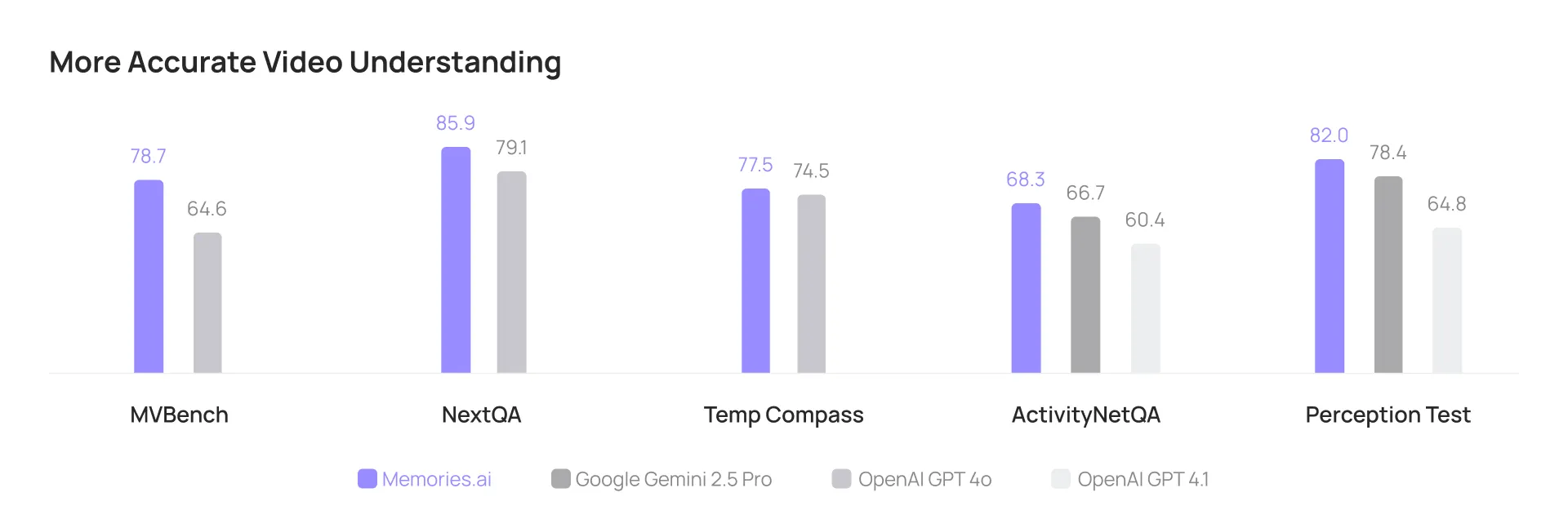
*Comparative data, including that from OpenAI and Google model systems, is sourced from the respective release blogs of OpenAI and Google.
Inspired by Human Memory Mechanisms
Have you ever wondered what our brains are truly doing when we struggle to recall a name, a scene, or an important date? Is it simply playing back a pre-recorded "film" like a video recorder?
The answer is: far more than that! Our understanding of human memory retrieval has delved into the microscopic level, revealing it as a complex and highly dynamic reconstructive process, rather than a mere playback. Each act of remembering is a fresh construction of information by the brain, based on current needs, emotions, and existing knowledge.
Inspired by these human memory mechanisms, we designed our initial memory model during the development of our Large Visual Memory Model. Specifically, it comprises a Query Model to transform memory cues into searchable requests, a Retrieval Model for coarse retrieval, a Full-Modal Indexing Model, a Selection Model for fine-grained detail extraction, a Reflection Model for memory monitoring, and a Reconstruction Model for memory reconstruction. To understand the memory retrieval process, we can break it down into several key steps:
1. Memory Cues: Igniting the Recall Process
Recall often begins with cues. These cues can be external, such as a question, an old photograph, a familiar melody, an incoming scent, or even a place name. They can also be internal, like a fleeting thought or a sudden emotion that crosses our mind.
When the brain receives these cues, they act like keys, activating specific neural networks associated with the target memory. Imagine your brain as a vast library, and cues are the catalog labels on the shelves, guiding you towards potential sections.
In our system, we employ a Query Model to convert cues (primarily text-based cues here) into concrete, searchable content. This involves steps such as text parsing and transcription, transforming cues into a format suitable for subsequent processing.
2. Coarse Retrieval: Initial "Screening"
Activation isn't always precise. The initial retrieval is often rough and generalized. The brain rapidly searches through vast amounts of information for patterns that best match the current cues. This is akin to quickly scanning book spines in a library to find titles or covers that might align with your needs.
At this stage, some relevant visual segments might be initially activated. This is a mechanism known as "cue-dependent recall"—the more precise and effective the cue, the faster the brain finds matching patterns, and the easier the recall becomes.
In our system, we utilize a Retrieval Model for coarse retrieval. For the query objects parsed in the previous step, the retrieval model selects appropriate databases and query methods to identify all relevant segments, alleviating "cue-dependent recall" and activating all relevant visual segments.
3. Fine-Grained Detail Extraction: In-Depth "Reading" and "Editing"
Once initial cues activate relevant areas, the brain moves into a more refined processing stage. Here, the reconstructive nature of memory begins to manifest.
In our system, we use a Full-Modal Caption Model and a Selection Model for fine-grained detail extraction. For all visual segments, our full-modal caption agent captions the key core content in conjunction with memory cues. The selection agent then performs deep reasoning based on all captioned content to select several most relevant visual segments, narrowing down the memory search range. This largely accomplishes the visual memory retrieval process.
4. Memory Monitoring: The Memory's "Self-Correction"
During recall, our brain also monitors and verifies the retrieved information, assessing its accuracy and authenticity. This involves comparing it with our existing knowledge, beliefs, and other related memories. If the recalled information contradicts known facts, we might experience a feeling of "this isn't right" and attempt to further recall or correct it.
In our system, we use a Reflection Model for memory detection and verification. When retrieved memory content conflicts with facts or is inconsistent, the process re-enters the fine-grained detail extraction phase.
5. Memory Reconstruction: From Fragments to a "Refined Version"
When we recall a complex event, we typically don't remember every tiny detail. Instead, the brain tends to extract the core gist of the event, the main actors, and the key outcomes. It filters out less important or redundant information, summarizing it into a more easily stored and retrieved form. This ability to abstract is key to efficient memory operation. The reconstruction process also involves integrating scattered memory fragments (e.g., visual snippets, sounds, emotions) into a meaningful pattern. The brain seeks connections between these fragments and organizes them into a coherent narrative or concept. This allows us to understand and tell a complete story, rather than just remembering a bunch of unrelated sensory inputs.
In our system, we use a Reconstruction Model for memory reconstruction. Based on memory cues and all currently retrieved information, it can identify information patterns and leverage world knowledge and logical reasoning to complete missing details. Simultaneously, it filters and refines irrelevant or redundant information, making the memory clearer. It also needs to integrate dispersed perceptual, conceptual, and emotional fragments into coherent, meaningful narratives or conceptual structures.